From Vibecoding to Engineered AI Development: My Journey with Coding Agents, Context Windows & Petri Nets
Over the last months I’ve been living in two worlds at once: the world of vibecoding – just throwing prompts at a coding model and hoping for magic – and the world of real software architecture, where constraints, edge cases and production incidents don’t care about vibes at all.
Somewhere between those two worlds I started building my own approach to coding agents, reasoning models and a Petri-net-based orchestration layer that keeps everything under control. This article is my attempt to capture that whole journey in one long-form, opinionated, technical brain dump – written for senior developers, architects and anyone who feels that “just prompt it” is not enough.
I’ll talk about:
- What I mean by coding agents & reasoning models
- Why vibecoding is powerful but dangerous
- How context windows really shape what an LLM can and cannot do
- Why developers must think in loops, not in single prompts
- How I use Petri nets as an orchestration layer for agents
- Why we still need another logical layer on top of LLMs, because they only predict the next token
This is not a generic “AI will change everything” article. It’s the essence of what I’ve been working out in this project: how to use coding agents as serious tools, not toys.
What I Mean by Coding Agents
When I say coding agent, I don’t just mean “the LLM inside my IDE that writes a for-loop.” I think in terms of roles and responsibilities:
- Reasoning models: large, powerful models that help with architecture, planning, tradeoffs, specifications, decomposition, and feedback on designs.
- Coding agents: models (often more specialized) that generate actual code, refactor, add tests, and perform mechanical transformations based on clear instructions.
- Execution agents: automated components that run commands, deploy artefacts, call APIs, execute migrations, or do other “real world” actions triggered by the previous two.
In my world, a “coding agent” is not autonomous magic. It’s one transition in an agentic process. It consumes context (tokens), produces outputs (tokens/code/patches), and is orchestrated by something bigger – a process, a Petri net, a higher-level agent that understands the overall goal.
Vibecoding: Powerful, Fun – and a Trap
Vibecoding is that feeling when you open a chat window and type something like:
“Build me a microservice that does X, Y, Z with OAuth, Kafka, retries, monitoring and a nice UI.”
You get back a wall of seemingly perfect code, you skim it, your brain says “Looks legit,” and you move on. That’s vibecoding. It’s useful. It can save hours. But it is:
- Non-reproducible: A slightly different prompt, different temperature, or a missing file in context and you get a completely different codebase.
- Context-fragile: Once the context window moves on, the model “forgets” design decisions it itself invented five minutes ago.
- Architecture-blind: The model doesn’t “own” the system. It only optimizes the next token, not long-term maintainability.
I don’t want to kill vibecoding. I want to domesticate it. Use it for exploration and speed, but embed it into a structured, loop-based, test-backed development process.
Reasoning Models vs. Coding Models
One core insight from my work: It’s a mistake to expect one model to do everything perfectly.
- Reasoning models (the big, “smart” models) are great at:
- Understanding vague, high-level requirements
- Finding gaps and contradictions
- Proposing architectures, patterns, and tradeoffs
- Explaining concepts and debugging complex issues
- Coding models / coding agents shine at:
- Generating boilerplate, scaffolding, adapters, DTOs
- Refactoring existing code according to clear rules
- Adding tests for a well-defined component
- Performing repetitive, localized changes
My agentic process is increasingly two-stage (or even multi-stage):
- Use a reasoning model with a large context window as an architect co-pilot to design the system, refine the plan, and define boundaries and interfaces.
- Use coding agents as specialized workers that apply those decisions consistently to the codebase.
Once you internalize this separation of concerns, a lot of pain disappears. You stop asking the coding agent to be your architect, product owner, QA engineer, and release manager at the same time.
Context Windows: The Real Working Memory of an Agent
Everyone talks about parameter counts and benchmarks. But in real-life coding agents, the context window is the hard constraint you hit every single day.
An LLM doesn’t have a long-term memory of your project. It has a sliding window of attention. Outside of that window, everything is gone – unless you explicitly bring it back in. That means:
- You cannot just “throw the whole repo at the model” and expect coherent, stable architecture decisions.
- You must curate what goes into context: relevant files, specs, current module, tests, constraints.
- You must treat the context window like a stack frame or working set, not like infinite RAM.
For developers and architects, this changes how we work:
- We need to design prompts as processes, not as single-shot questions.
- We need to stepwise build context for the agent: first the spec, then the interfaces, then the implementation.
- We need to persist key artefacts (architecture docs, decisions, contracts) in a way we can reload them into context when needed.
In other words: someone has to manage the context window. That someone is currently still the developer/architect – or, in my experiments, a higher-level agent combined with a Petri-net orchestration.
Thinking in Feedback Loops, Not Single Prompts
One of the biggest mindset shifts for me was to stop treating a prompt as a one-time request and start treating the whole interaction as a loop.
- Planning loop: You describe the idea. The reasoning model proposes a plan. You challenge it. It refines. You iterate 10–50 times until the first module is well-defined.
- Coding loop: Based on the stable plan, coding agents implement a concrete slice: one service, one module, one transition.
- Testing & review loop: Agents run tests, generate additional tests, explain failures, propose fixes. You verify, prune and accept.
- Refinement loop: Reasoning model and coding agents work together to clean up the architecture, remove duplication, and improve observability.
Notice what this implies: the agent is not in control of the loop. The loop is part of the architecture. In my case, I model these loops explicitly using Petri nets and transitions that represent agent calls, human reviews, tests, deployments, and so on.
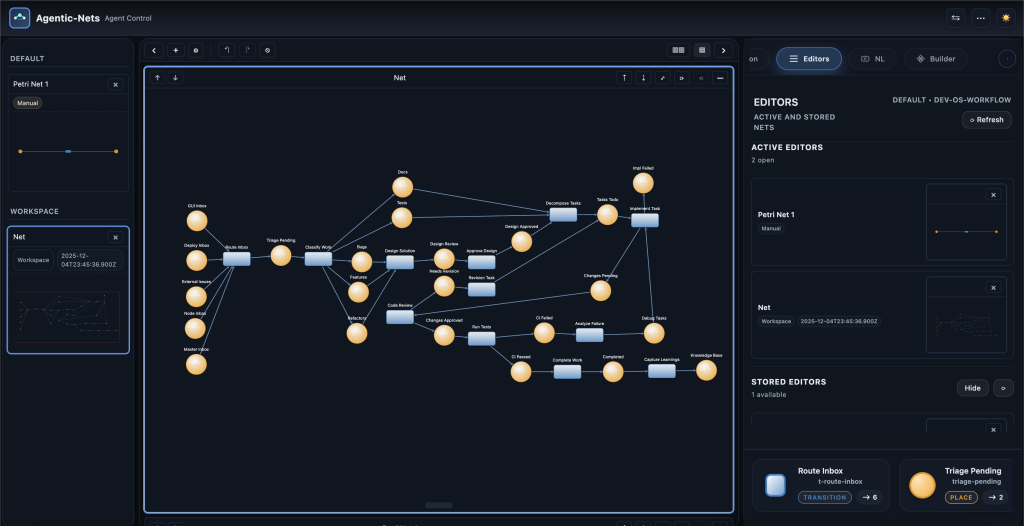
Petri Nets as the Orchestration Layer for Coding Agents
Petri nets have been with me for a long time (literally since my diploma thesis). With modern agents, they suddenly feel weirdly perfect again.
In my current work, I use Petri nets as a visual and executable model of agentic processes that involve both humans and agents:
- Places hold tokens that represent state: specs, tasks, code patches, test results, emails, API responses, etc.
- Transitions represent actions:
- HTTP transitions that call REST APIs
- LLM transitions that call a reasoning model
- Coding transitions that call coding agents
- Command transitions that execute real commands on remote executors
- Guards & inscriptions control when and how tokens move, and how agent calls are parameterized.
This gives me something that tools and pure prompts do not:
- Explicit control flow: I can see and change how work moves through the system.
- Concurrency & synchronization: Multiple agents and actions can run in parallel, but the net ensures consistency of tokens.
- Human-in-the-loop integration: Human review is just another transition; it consumes and produces tokens like everything else.
- Observability: Tokens and transitions produce metrics (for Prometheus/Grafana, etc.), so I can see where work gets stuck.
From this perspective, a coding agent is simply one kind of transition with a specific inscription that knows how to talk to the LLM and interpret the result.
Command Transitions & Remote Executors
An important refinement in my architecture was to separate command transitions from everything else.
Today, I treat transitions that actually execute real-world commands differently:
- Most transitions (LLM calls, HTTP calls, mapping, analysis) are executed directly on the master node that manages the Petri nets and tokens.
- Command transitions are deployed to remote executors which:
- Poll for work from the master (outbound-only connections)
- Receive tokens representing commands & context
- Execute them (e.g., deploy a container, run a script, compile code)
- Emit new tokens back into the net
This poll-only architecture keeps the central master clean and secure, and isolates risky or heavy actions into executors. For coding agents, this is powerful: the agent doesn’t just write code, it can also trigger real actions – but always inside a controlled agentic process.
Agent Inscriptions: Giving LLMs a Native Interface to the Net
One particularly exciting direction is to give agents a native inscription interface to the Petri net itself.
An agent inscription is like a specialized connector between the LLM and the Petri net runtime. It should allow the agent to:
- Access both design-time (model) and runtime (tokens, state) information.
- Iterate in loops: call the LLM, inspect tokens, revise plan, call again.
- Emit tokens autonomously based on the model: the agent decides what tokens to create and where to route them, within the defined preset/postset.
- Use hints from the inscription, presets and postsets to better understand which actions are possible and valid.
The key idea: the agent doesn’t just answer a prompt; it navigates a net. The Petri net defines the space of valid moves, and the agent chooses within that space. This massively reduces risk and hallucination impact compared to “free roaming” agents.
Why LLMs Still Lack Logical Decision-Making
We have to be brutally honest here: LLMs are not logical engines. They are next-token predictors trained on massive datasets. That gives them:
- Impressive pattern recognition
- Great “knowledge compression” of common code, patterns and architectures
- Surprisingly useful emergent reasoning in many everyday tasks
But it also means:
- They can confidently walk into dead ends (e.g., inventing functions, APIs or design patterns that don’t exist).
- They can get stuck in feedback loops, generating variations of the same wrong idea again and again.
- They do not have a built-in global objective like “maximize consistency of this entire project over six months.”
From my experience, you cannot fix this by “prompt engineering harder.” You need another layer on top that:
- Defines what success and failure mean for each step.
- Decides when to stop asking the LLM and change direction.
- Coordinates multiple models and tools.
- Imposes constraints and boundaries (e.g. via Petri nets, state machines, or similar formalisms).
A coding agent alone is not a team lead. It’s a brilliant but naive junior developer. You still need a structure around it – and that’s where my whole work on orchestration, Petri nets and agent inscriptions comes in.
Real Use Cases I Explore with Coding Agents
These ideas are not purely theoretical. Some of the directions I’ve been exploring include:
- Software development agentic processes
- Using a design agent to create a net describing a complete development process.
- Modeling requirements refinement, architecture, implementation, tests and deployment as tokens and transitions.
- Attaching coding agents to specific steps: generating DTOs, mapping layers, tests, configuration.
- HTTP and API orchestration
- Transitions that encapsulate HTTP calls, including authentication, retries and error handling.
- Agent-assisted mapping of unstructured requests into the right API calls.
- Email analysis agents
- Places that store metadata tokens for emails.
- LLM transitions that classify, summarize, or extract tasks from emails.
- Command transitions that trigger follow-up actions (tickets, replies, updates) in a controlled way.
- Git repository analysis
- Streaming through commit history, extracting semantic changes and tokens per commit.
- Using LLMs to understand development intensity, hotspots, and quality trends.
- Building indexes and scores that represent the “health” of a project.
All of these benefit from the same pattern: let agents do the heavy semantic lifting, but keep them plugged into a formal, observable agentic process that I can reason about, debug, and evolve.
Principles I Follow When Working with Coding Agents
If I had to compress all of this into a few practical principles for developers and architects, it would be these:
- 1. Separate thinking and doing.
Use reasoning models to clarify what you want, then use coding agents to implement it. Don’t mix both in the same chaotic prompt. - 2. Treat the context window as a resource.
Curate what the agent sees: give it the minimal but sufficient context for the task at hand. Don’t flood it with the entire repo. - 3. Build loops, not monologues.
Design feedback loops: plan → implement → test → review → refine. Represent them explicitly, e.g. in a Petri net. - 4. Keep humans in the loop.
Critical decisions, security-sensitive actions and architecture-level changes still need human judgment. - 5. Isolate execution.
Run dangerous or irreversible actions (deployments, scripts, migrations) in controlled command transitions on remote executors. - 6. Observe everything.
Ensure that transitions create metrics and logs. See where tokens flow. Use dashboards to understand your agentic system. - 7. Accept that LLMs are fallible.
Build guardrails, retries, validation steps and rollback strategies, instead of expecting the agent to “just be right.”
Conclusion: Adding a Real Architecture Around Vibecoding
Vibecoding is here to stay. It’s too powerful and too convenient to disappear. But as systems grow, as we start letting agents touch production, as we connect them to email, Git, Kubernetes, billing and more, we simply cannot afford to rely on vibes alone.
We need structure:
- Structure in how we plan (reasoning loops).
- Structure in how we code (coding agents as transitions).
- Structure in how we execute (command transitions and remote executors).
- Structure in how we orchestrate everything (Petri nets, tokens, observability).
Large language models are amazing pattern machines, but they are not yet reliable strategic decision-makers. They can simulate logic, but they do not possess a stable global objective. That’s why we need this extra architectural layer – a formal, observable, controllable system that uses LLMs as components, not as gods.
For me, that layer is deeply inspired by Petri nets, event-driven architecture and distributed systems. For you, it might look slightly different. But the core idea will be the same:
Don’t just ask the agent to build the system. Build the system that safely and intelligently uses agents.
That’s the essence of what I’ve been working out here – and it’s only the beginning.